

As a Lead AI Engineer, I have been involved in developing and integrating AI enabled products and services into Deutsche Telekom’s ecosystem. Because Generative AI technology is relatively new, there is not a lot of experience out there on how to evaluate and proceed with the capabilities that AI offers. Therefore, in this article I will give my own personal experiences and lessons learned.
Lesson learned #1 - Keep AI researchers available
The most important, underlining lesson in all the points I will be giving in this article is, that companies internally struggle to understand and discern where Generative AI is really useful and where in its current technological state it lacks promised capabilities.
My personal belief is, there is an extreme amount of hype in the market. Companies and individuals make rather unwarranted claims about their achievements. I have yet to see a transformative Generative AI integration (maybe except call-centers).
However I also believe, Generative AI and technologies that it spawns further down the line (e.g. Large Reasoning Models - LRMs) are and will be increasingly useful to bring added value. That’s why we argue in our white paper https://www.researchgate.net/publication/383084990_The_Human-AI_Synergy_Redefining_the_Role_of_Generative_AI_in_Strategic_Planning_and_Decision_Making that companies must keep critical amount of deep AI research capabilities accessible, so they can rapidly understand which AI use case can be profitable and which maybe not so much.
The study AI Talent: Act Now Before It’s Too Late also reveals that AI researchers are currently the #1 job category sought by employers among technology roles, with nearly 30% of large businesses seeking this specialized talent. The demand for AI researchers in private industry has grown 3.5x over the last decade to 70%, while supply growth will stagnate at just 4% in the coming years. This scarcity is particularly acute since only about 20% of graduating computer science PhDs have specialized in AI, driving entry-level salaries to $180K-$200K with projected compound growth of 20%. According to Pluralsight's study of 1,200 decision makers, only 10% of companies fully understand their current or future AI skill profiles, emphasizing how crucial AI research capabilities are for distinguishing valuable AI opportunities from hype.
Trough of Disillusionment
Executive Board Member of Deutsche Telekom, Claudia Nemat, has expressed this sentiment:
“The AI hype is ending," according to the media – and that would be good news. Why is that? Finally, we can focus on creating value with AI. Instead of worrying about cycles, inflated expectations, or disillusionment… (https://www.linkedin.com/posts/claudianemat_ai-generativeai-genai-activity-7234455288290897922-Cv9c)
On the other hand, the main issue we are facing with AI hype potentially dying down is, that the pendulum for some companies will now swing too much to the other side. That would mean less investments and engagement with potentially valuable AI technology integrations.
As management and engineers were for last few years generally lead to believe, that it is enough to just “throw AI at the problem”, which quite apparently hasn’t been proven, there is a real threat for companies they will underinvest.
Companies need to keep AI researchers and engineers available, so that they can ground positive or negative sentiments in facts.
Some companies will be successful in acquiring and maintaining AI talent. This will result in AI “winners”, very similarly to the internet “winners” after the Dotcom bubble in the beginning of the millennium (Google, Amazon…).
Lesson learned #2 - Be grounded in facts
Generative AI, like ChatGPT from OpenAI or Claude from Anthropic, is smart, but not smart enough when compared to people. Let’s consider the
https://simple-bench.com/ benchmark.
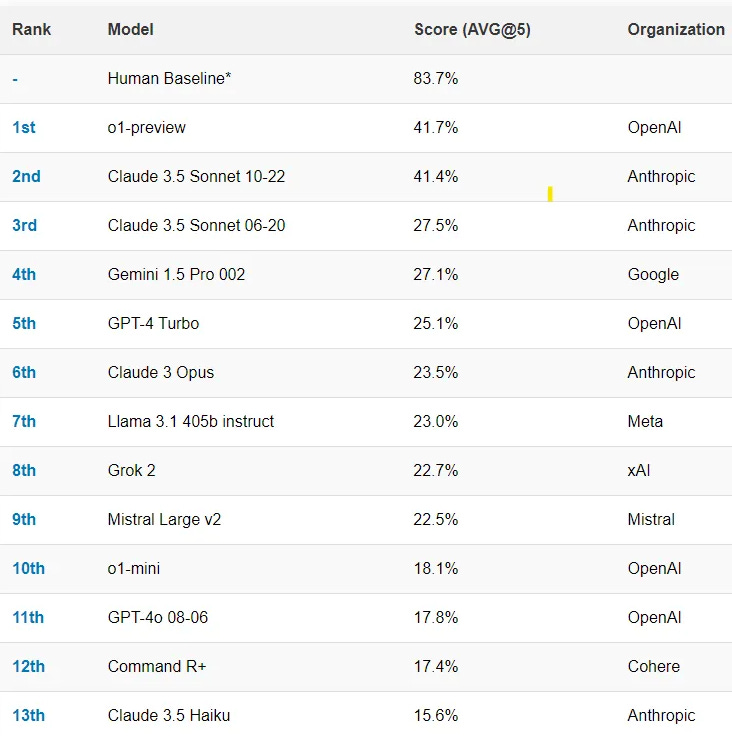
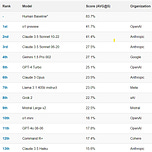
Regarding spatial, temporal and social questions, GenAIs are exhibiting considerably lower capabilities when compared to human baseline (83.7%).
Let’s consider this example question from https://simple-bench.com/:
Beth places four whole ice cubes in a frying pan at the start of the first minute, then five at the start of the second minute and some more at the start of the third minute, but none in the fourth minute. If the average number of ice cubes per minute placed in the pan while it was frying a crispy egg was five, how many whole ice cubes can be found in the pan at the end of the third minute?
The answer is 0, because on a hot frying pan no ice cubes would be left. This is rather obvious to people, but Large Language Models (LLMs) quite often miss the point.
World we live in is very complicated and noisy. Not every question or problem that we are facing is clear-cut and well defined. It is apparent, that in such scenarios Generative AI technology is struggling.
Why is this important?
There are several systems that promise agentic or self-running behavior on behalf of humans. Some more famous examples are https://devin.ai/ or https://github.com/yoheinakajima/babyagi. The key point to always discuss with such promises is to look at the capabilities of underlining Large Language Models (LLMs) or LRMs. These LLMs or LRMs are the engines, or drivers for the agentic systems. Meaning, that if the underlining engine is not capable enough, the whole integration will not work.
There are two concrete example from my experience.
1. Example
At Deutsche Telekom we are developing a Neuro-Symbolic AI product called Advanced Coding Assistant (ACA). One of its features is agentic behavior.
ACA is capable of dynamically retrieving data from a database based on user questions. It is doing so by creating small AI agents in its internal environment and giving these AI agents tasks.
One capability we originally tried to implement was, to ask these AI agents whether they “think” the retrieved information seem to suffice based on user questions. Most of the times the AI agents never called a stop on the process, essentially extracting the whole database in the end.
We had to actually give ACA a hard limit of how many times AI agents can retrieve data from the database and we also had to set up a hard limit for tokens that can be extracted from the database.
A human understands that it is almost never possible to have all the required information and so we as human beings are able to work in limited information spaces.
Generative AIs, on the other hand, exhibit a more sycophantic behavior, meaning they always want to comply to user requests and “do more” whenever possible.
We could argue that this is due to fine-tuning, nevertheless, it is very clear to us as AI experts, that fully relying on these AI systems is not possible at this moment.
2. Example
We have detailed the experiment setup in our white paper https://www.researchgate.net/publication/383084990_The_Human-AI_Synergy_Redefining_the_Role_of_Generative_AI_in_Strategic_Planning_and_Decision_Making, but the essence of the experiment is that we pitted two GPT-4s to play a simple board game against each other.
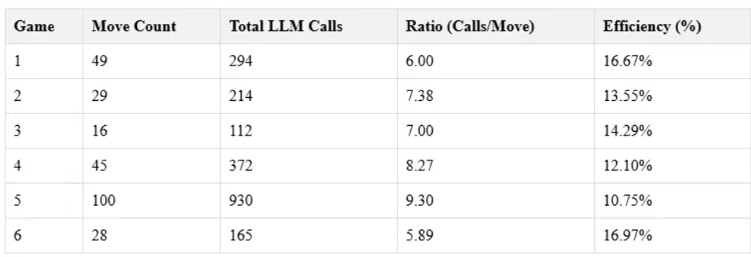
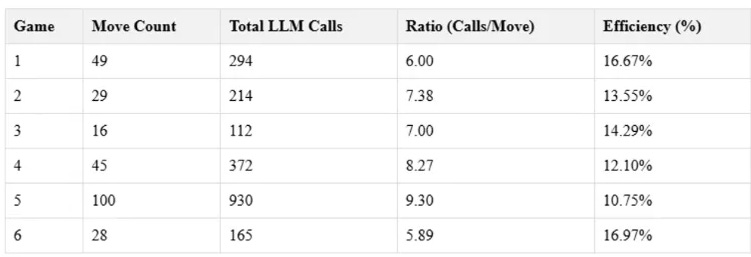
These are the results:
LLMs struggle with consistent rule application, even in simple game environments. On average, it took between 5.89 to 9.30 LLM calls to make a single valid move, indicating difficulty in understanding or applying basic game rules.
Decision-making efficiency was low, with only 10.75% to 16.97% of LLM calls resulting in valid moves. This inefficiency could be problematic in real-world scenarios requiring quick, accurate decisions.
As games progressed and became more complex, LLM efficiency tended to decrease, raising concerns about scalability in more intricate, long-term planning scenarios.
The experiment incurred substantial computational costs (approximately 50 to 100 euros per hour) while producing no tangible strategic gains, highlighting potential economic inefficiencies in deploying LLMs for complex decision-making tasks.
Hyperscalers like Google, AWS or Microsoft are can be so successful (and expensive), because they provide extremely high reliability within their clouds:
AWS - 99.99% reliability (https://www.ccslearningacademy.com/azure-vs-aws-reliability/)
Azure - 99.995% reliability (https://www.ccslearningacademy.com/azure-vs-aws-reliability/)
GCP - 99.99% reliability (https://cloud.google.com/compute/sla)
It is clear that frontier LLMs like GPT-4 with efficiency (reliability) 10-17% cannot be part of any automated or agentic system.
The reliability rates will get better (e.g. LRMs), however at this current point in time LLMs are not useful enough in more sophisticated autonomous systems like coding. Counterintuitively, trying to build automated systems may be more expensive than to keep even very expensive employees.
Lesson learned #3 - Experimental/PoC phase
Within Machine Learning (ML) field there is a clear notion of having to prove expectations or hypothesis with experiments. We can think of them as Proof of Concepts (PoC) in software development.
The reason why experimental phase in ML is so well established is because ML/AI systems are random to a degree. They are stochastic and functioning based on statistics, not hard rules like typical software.
With the hype surrounding AI today, many people including engineers and management, believe the AI technology is already super-human. In some regards it is, but as we have seen in the ‘Lesson learned #2 - Be grounded in facts’ section, AI is far from being perfect.
Therefore, companies should not forget to prepare experimental phases for potential AI integration and prove that their assumptions with AI use cases are true.
Management doesn’t like to hear it, but that essentially means allocating resources towards experiments, which may prove to be not viable! And furthermore, management and engineers need to be brave enough to admit, that the experiments didn’t prove the assumptions. This completely changes the paradigm of software development. And that’s OK!
I personally expect there will be a shift in the future more towards experiments and PoCs with AI use cases. But that will take some time and courage on the companies part.
But if companies can be internally honest about the AI experiments, it will save a lot of resources.
Lesson learned #4 - Make or buy?
Generative AI tech is very new. Even tech giants that have extensive experience with AI and ML and are producing AI enabled products, like Google or Microsoft, don’t quite understand yet how and where this technology may be useful the most (https://techcommunity.microsoft.com/discussions/microsoft365copilot/microsofts-copilot-a-frustrating-flop-in-ai-powered-productivity/4221190). On the other hand, other companies have to take into account that AI talent is not widely available and is quite expensive (https://thecuberesearch.com/ai-talent-act-now-before-its-too-late/).
So how should companies which weren’t historically directly ML/AI driven know whether they should wait for the market to provide AI products or to try and develop their own solution?
Example from Deutsche Telekom
Initially, when the AI hype started with the release of ChatGPT, we came up with an idea of “AI Analyst” directly connected to CICD pipelines:
The AI Analyst was meant as a tool, that would help developers quickly analyze commits which potentially contain bugs. We’ve done some small manual experiments with ChatGPT and the results looked promising.
However, I didn’t take into account the token limit count (back than it was about 16.000), meaning not a lot of information could be squeezed into one prompt.
Natural question came up, how do we scale this idea? Sure, simple manual experiments look nice, but how do we automate? Furthermore, what is the reliability of this system? Wouldn’t it actually decrease developer/devops productivity, because there are a lot of false positives? What about the costs associated with AI, which are pretty high to run such system? Are the costs warranted?
Even today with high token limits, it is questionable whether this system would provide high enough productivity boost compared to the costs it can incur (https://towardsdatascience.com/the-needle-in-a-haystack-test-a94974c1ad38).
Organizations eager to capitalize on the AI trend often develop grandiose initiatives based on unsubstantiated assumptions. These assumptions frequently stem from anecdotal evidence shared by other departments or companies, who themselves are caught up in the AI excitement and publish informal case studies and experiences. This creates a self-reinforcing cycle of hype, where decisions are driven by speculation rather than solid research or a genuine understanding of what Generative AI can actually achieve.
All these uncertainties can be answered with quite high confidence if companies keep some AI researchers and engineers at hand and conduct honest experiments and PoCs (Lesson learned #1, Lesson learned #3).
So what would be my recommendation on whether to develop or buy?
Cloud and platform providers typically develop AI products that surpass what organizations can build internally. These providers have access to vast datasets and user feedback, enabling them to create more effective AI integrations. If major providers haven't implemented a specific AI feature you're considering, it may indicate technical or practical limitations that make it unfeasible. Their development timeline may be longer than desired, but their solutions are generally more robust and battle-tested. For example https://aws.amazon.com/q/ and Deutsche Telekom askT:
Before starting your own AI implementation, check with your platform providers about their development roadmap and upcoming features that might address your use cases.
However, if there still is strong internal sentiment, that a particular AI use case could be feasible, then you have to revert to Lesson learned #1 and Lesson learned #3:
You need AI researchers and engineers
Device an experiment/PoC in cooperation with them, which would prove or disprove you assumptions
Only after the experimental phase has proven, that the product is reliable, safe, scalable and also cost-efficient, only after that it makes sense to continue with development for such a use case.
Conclusion
The future belongs not to those who blindly adopt AI, but to those who understand precisely where and how to apply it effectively.
